NanoPi R4SE
adorable. just. adorable. but also I hate you.
About a month ago I ordered both the r4s and r5s from nanopi.
Then a week or two after that they released the r4se, which is the same platform as the r4s but with 32gb of emmc onboard.
I ordered two of those.
This post is about openwrt on the r4se. I’m also playing around with opnsense on the r4s, there’ll be posts about that later.
Initial thoughts

This thing is is heavy, chunky, and very solid feeling. Build quality is excellent, all the ports line up perfectly with their openings.
The silkscreened labels line up perfectly with their respective openings/lights.
Overall a very nice unit.
The power supply they bundled isn’t the best looking thing, but it doesn’t get hot under load and it’s rated for 4 amps (r4s rated draw is 3a), so I’m happy with it.
The Firmware
The newest official firmware from friendlyelec is based on openwrt 21.02.
That’s a little old for my liking, thankfully they have a testing image based on 22.03.
Flashing the firmware to the emmc using rkdevtool took a bit of brain-ing to figure out, but I got there.
Setting up
First thing I did was add allow rules for tcp/80 and tcp/22 on the wan interface so I can access the DUT from my desktop.
After that I edited /etc/hotplug.d/net/40-net-smp-affinity to pin the rps for each interface to the fast a72 cores.
friendlyelec,nanopi-r4s)
set_interface_core 10 "eth0"
echo 10 > /sys/class/net/eth0/queues/rx-0/rps_cpus # was 3f
set_interface_core 20 "eth1"
echo 20 > /sys/class/net/eth1/queues/rx-0/rps_cpus # was 3f
;;
For some reason they were spread across all cores by default, even though they were pinning the irqs to the a72’s.
Finally I set the cpu gov. to performance in the webui. This only affected the a53 cores for some reason, so I put this in /etc/rc.local to force the cpu freq to max.
echo 1512000 > /sys/devices/system/cpu/cpu0/cpufreq/scaling_min_freq
echo 1512000 > /sys/devices/system/cpu/cpu1/cpufreq/scaling_min_freq
echo 1512000 > /sys/devices/system/cpu/cpu2/cpufreq/scaling_min_freq
echo 1512000 > /sys/devices/system/cpu/cpu3/cpufreq/scaling_min_freq
echo 2016000 > /sys/devices/system/cpu/cpu4/cpufreq/scaling_min_freq
echo 2016000 > /sys/devices/system/cpu/cpu5/cpufreq/scaling_min_freq
Worth noting is that on the 21.x series, the max configurable frequency of the a72’s is lower, 19xx-something vs 2016000 on 22.x.
Where’s my eth1?
After a soft retoot, eth1 had disappeared! Smells like typical realtek shit. I wish they had spent the extra 5 bucks on intel chipsets.
Makes me wanna design my own tiny router…. not that I’ll ever do that.
A hard powercycle brought it back. :thonk:
I rebooted a bunch more times, and eth1 disappeared about 1/5 of the time.
That’s acceptable for use at my home, but it means I wouldn’t really trust it anywhere remote.
But yeah. Imagine like. A really fast arm cpu with a lot of ddr4 memory. Dual nvme slots so you can raid 1. Good intel nics, like the i350 for four ports.
Sure, such a thing would have to be a bit bigger. And more expensive. But still. It’d be nice.
Maybe we’ll start seeing arm thin clients with pcie slots. That’d be almost perfect.
List of benchmarks to run:
// Typical home network traffic
lan <-> wan outbound nat
// Inbound port forwards
wan <-> lan inbound nat
// LAN to the device itself - NAS, etc
lan/wan <-> r4s
// We'll run these later on (probably in a different post)
// Openvpn
wan (openvpn client) <-> lan
// Wireguard
wan (wireguard client) <-> lan
Testing methodology:
We’ll run our tests using iperf3 and T-Rex.
If you’ve been reading my posts about T-Rex, you already know about our traffic generator.
It’s a dell optiplex 7040 with an i7 and a x710-DA2.
We already know that it can generate 10gig line rate at 64b on-frame, far more than our DUT can do.
Cursory speedtest.net testing
speedtest-cli from my laptop on the lan port shows about 300/300, which is about what I get here (yay fios).
So we know the r4s can NAT at least that much.
Benchmark the first: LAN <-> WAN w/ NAT
Some cursory benchmarking with T-Rex in stateless mode yielded some… Interesting results:
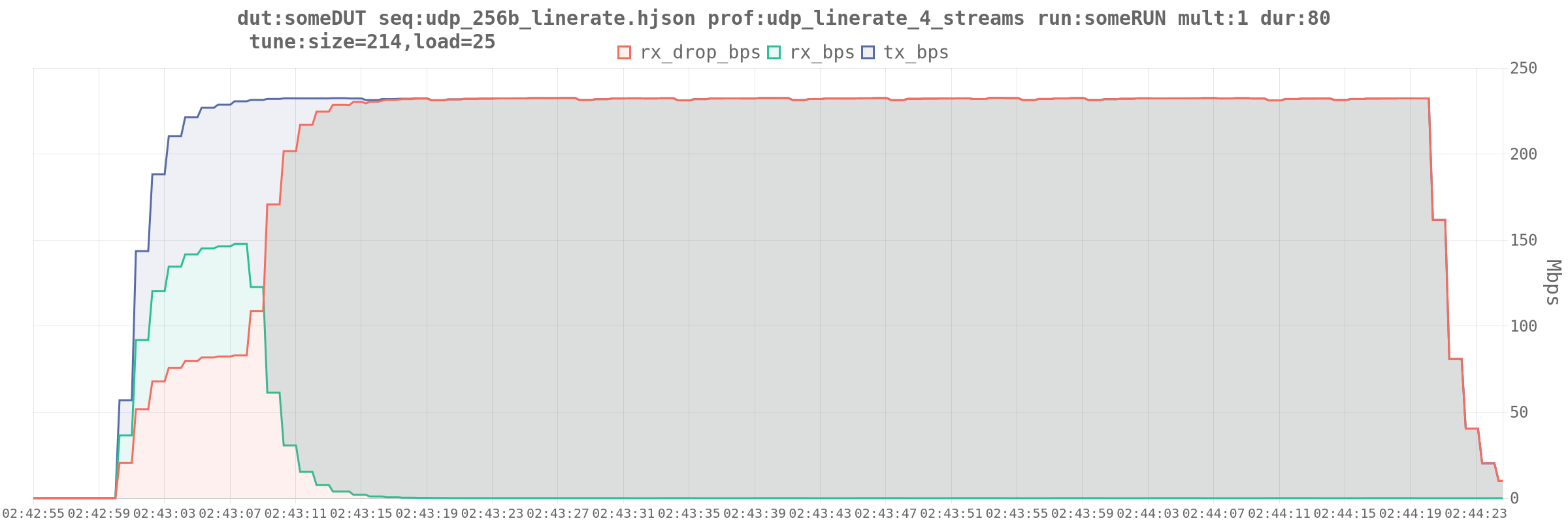
This was very repeatable with stateless profiles and scaled with load. I’d get a few seconds of about 30% drop, and then it’d go to near 100% drop.
Why you do that?
I started by examining my test setup. My thought was that some weirdness was happening with buffers.
If not there then maybe something at layer4 or higher…
First i looked at the network buffers and some other maximums on the DUT:
root@FriendlyWrt:~# cat /proc/sys/net/netfilter/nf_conntrack_max
65535
root@FriendlyWrt:~# sysctl net.ipv4.tcp_rmem
net.ipv4.tcp_rmem = 8192 262144 67108864
root@FriendlyWrt:~# sysctl net.ipv4.tcp_wmem
net.ipv4.tcp_wmem = 8192 262144 67108864
root@FriendlyWrt:~# sysctl net.core.rmem_max
net.core.rmem_max = 67108864
root@FriendlyWrt:~# sysctl net.core.wmem_max
net.core.wmem_max = 67108864
Those look reasonable to me. So why it do that?
Wireshark time
Spoiler alert - this didn’t tell me shit other than confirming that:
- my packets are the size on-wire that I thought they were (yay, no more math!)
- the DUT was properly doing nat
Had I been a bit more observant here, I would have saved some time. But let’s not spoil the surprise.
This is getting into weird territory. I’m going to get opnsense working on the r4s (non-emmc) and see how it handles these tests.
But first…
Let’s try ASTF
I mean, that’s what we’re supposed to be using, given that this lil guy is doing NAT.
Here’s a run of 64b on-wire frames. I think I’m near the limits of what this DUT can handle at this packet size.
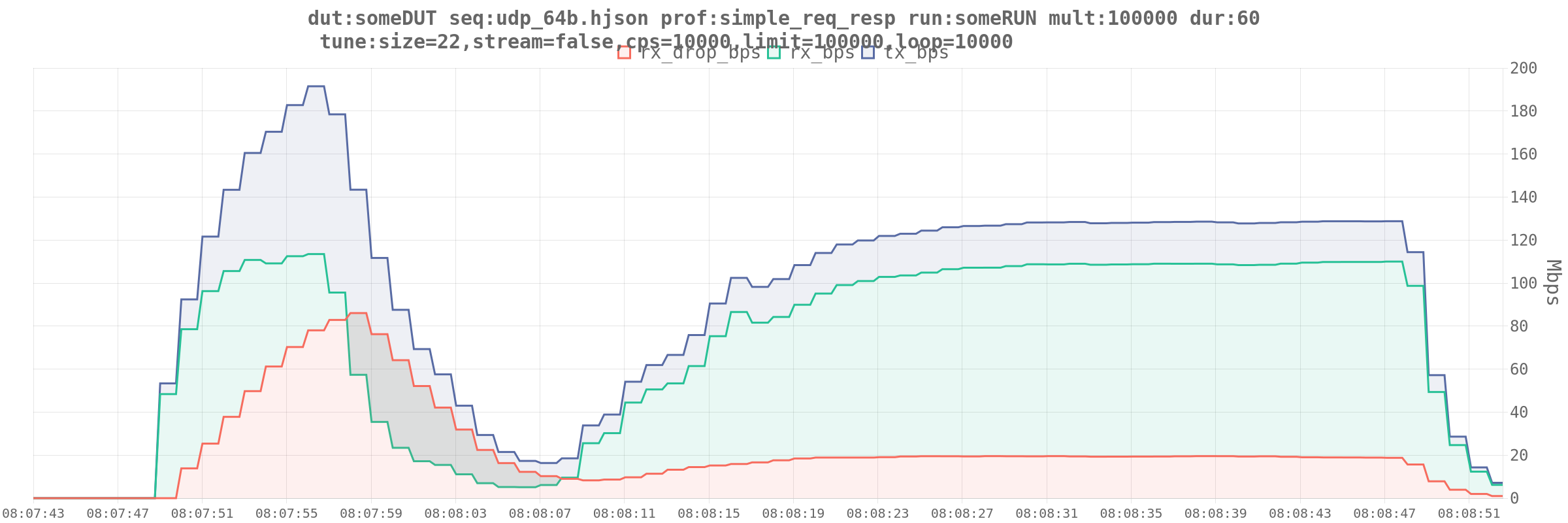
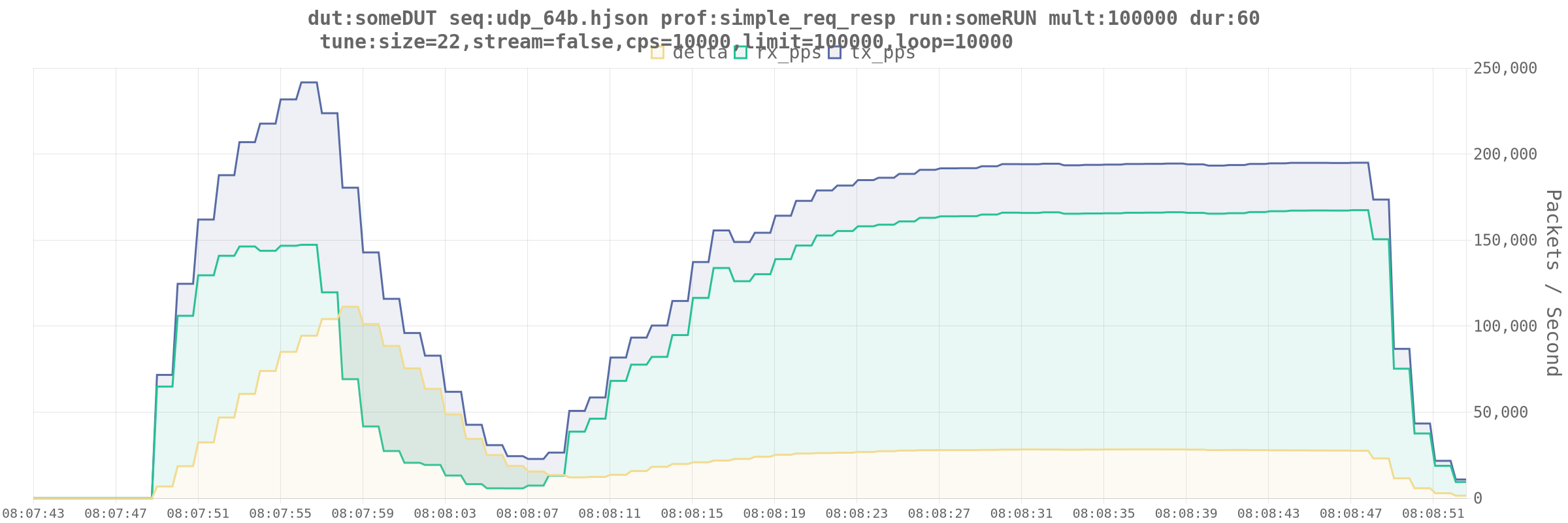
It’s always DNS ARP
So with ASTF profiles looking normal-ish, let’s go back to STL and see why that’s doing what it does.
I started doing a google for anything network io cache or timeout related.
On a hunch, I started this on the DUT: while true; do clear; ip neigh; sleep 0.5; done , fired off a STL profile and waited.
11.11.11.2 dev eth1 lladdr 3c:fd:fe:c6:06:10 STALE
10.15.41.1 dev eth0 lladdr a0:36:9f:83:b5:58 REACHABLE
12.12.12.2 dev eth0 INCOMPLETE
Wait, what?
Our configuration for t-rex itself looks like this:
- version: 2
interfaces: ['01:00.0', '01:00.1']
port_info: # 0 = client, right, 1 = server, left
- ip: 11.11.11.2 # phy port 0, client subnet is routed through this address
default_gw: 11.11.11.1 # r4s lan port
- ip: 12.12.12.2 # phy port 1, server subnet is routed through this address
default_gw: 12.12.12.1 # r4s wan port
On the DUT we have secondary addresses configured on “WAN” and “LAN” of 12.12.12.1/30 and 11.11.11.1/30 respectively.
Then we have routes:
16.0.0.0/8 via 11.11.11.2
48.0.0.0/8 via 12.12.12.2
So when the stateless profile starts:
- t-rex sends out a garp for 11.11.11.2 and 12.12.12.2
- openwrt sees this and installs the neighbor entry
- traffic flows for a while
- t-rex hasn’t sent another garp and isn’t responding to arp
- openwrt ages out the arp entry
- traffic dies off
- goos is confused
My googling brought me to many interesting pages including some functions in the python library that I can’t figure out how to replicate,
including one c.arp() which appears to send a garp on demand.
So how do we fix it?
We go back to the old ways and set static neighbor entries.
ip neigh add 11.11.11.2 lladdr 3c:fd:fe:c6:06:10 dev eth1 nud permanent
ip neigh add 12.12.12.2 lladdr 3c:fd:fe:c6:06:11 dev eth0 nud permanent
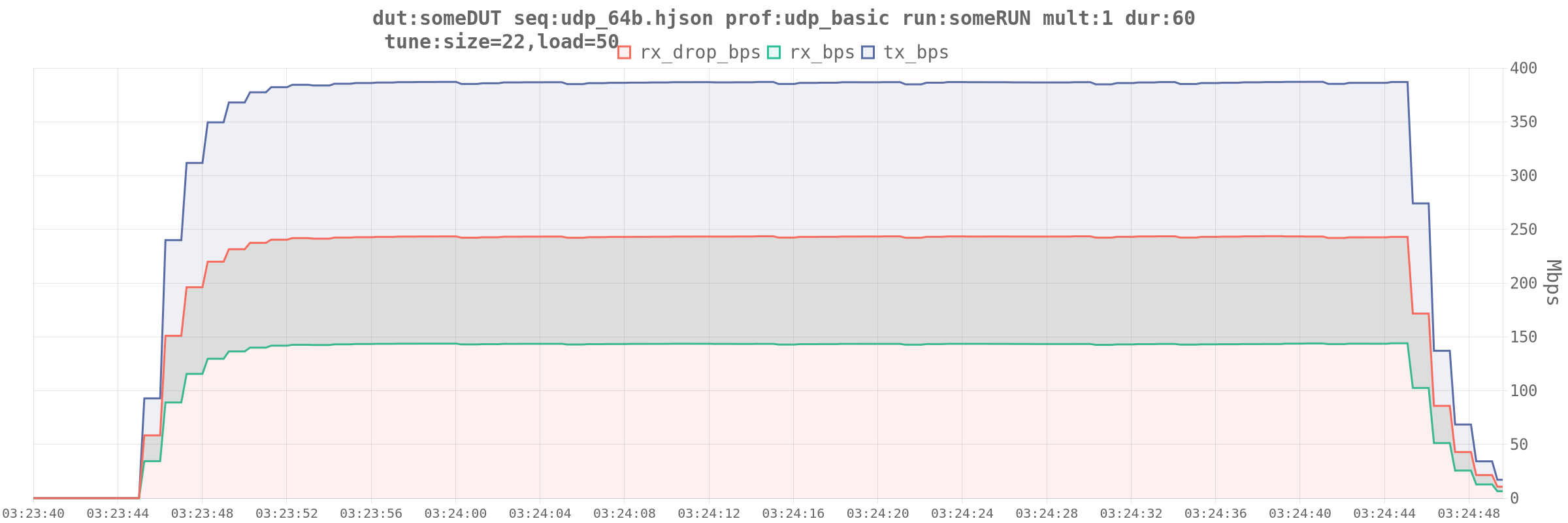
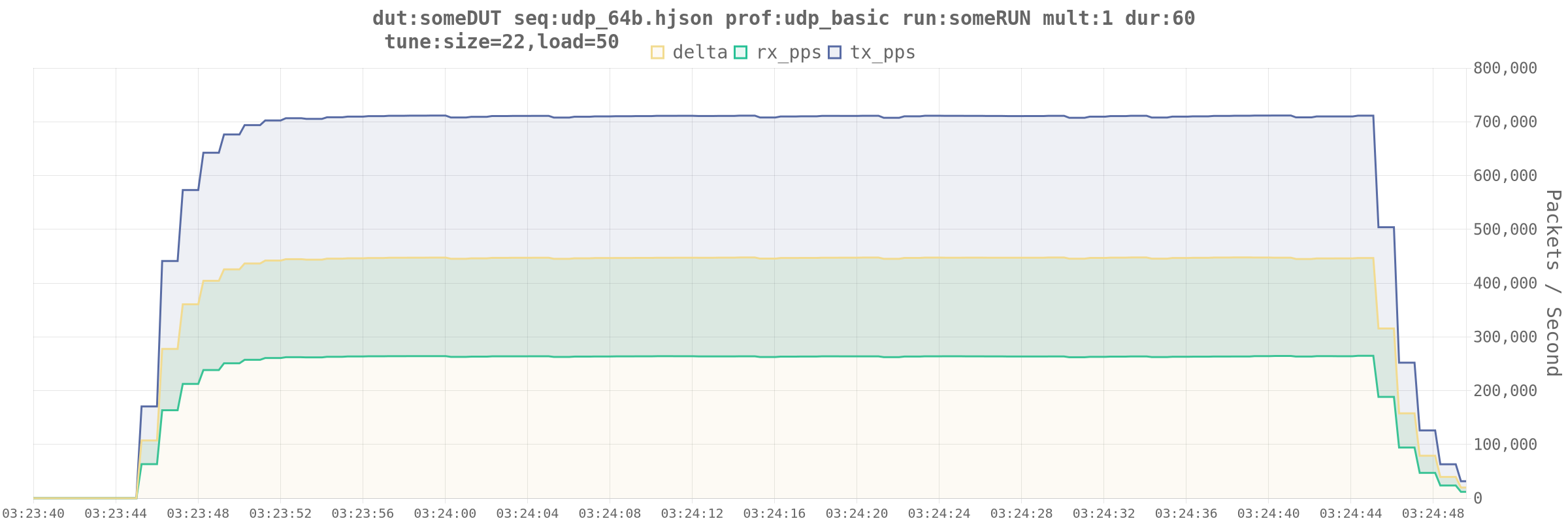
64b packets hurt, but it’s like. working now.
Still reading?
This is getting pretty long, and I haven’t done 10% of what I wanted to.
I’ll leave you with this:
Whenever you have connectivity problems. Check address resolution first.
If that’s DNS, ARP, some service discovery like consul, whatever.
Check that things know where things are before doing a deep dive.